Music Genre Classifier
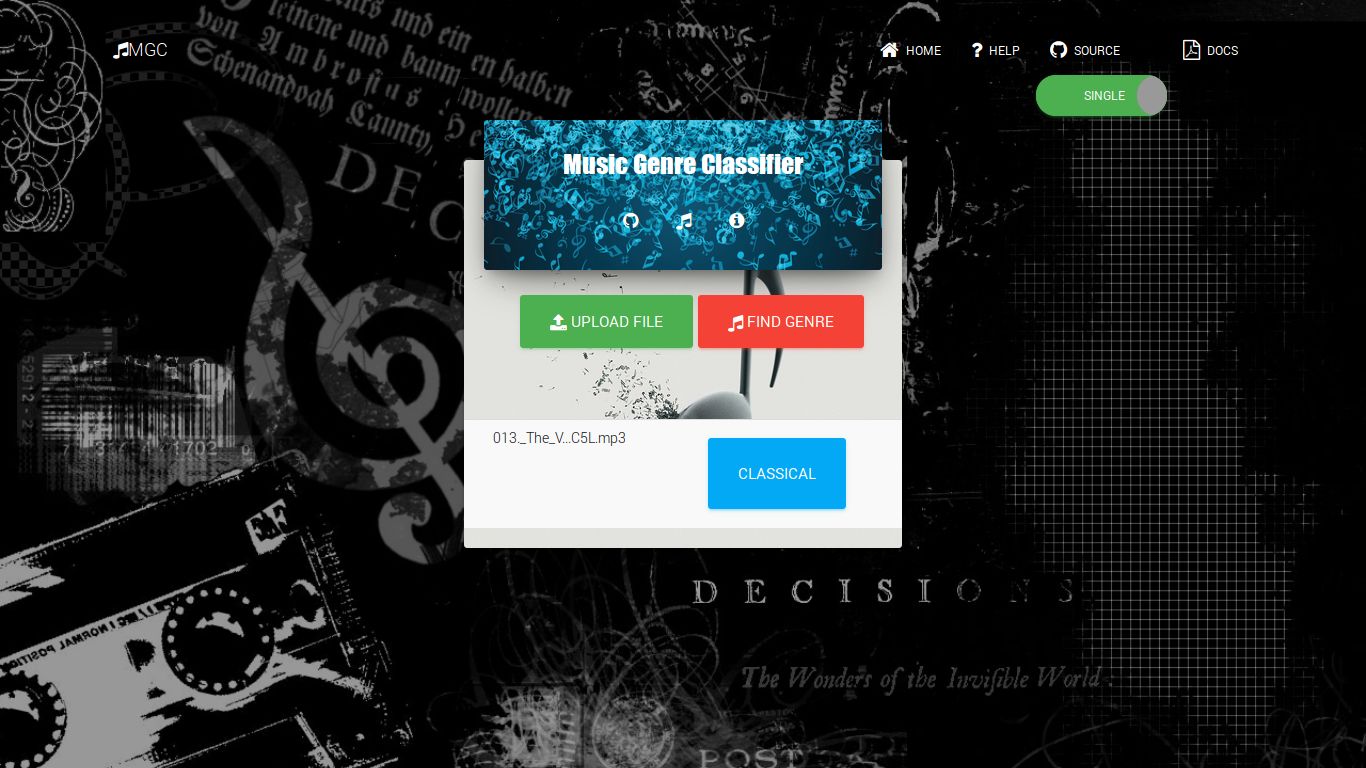
Demo
Music is categorized into subjective categories called genres. With the growth of the internet and multimedia, systems applications that deal with the musical databases gained importance and demand for Music Information Retrieval (MIR) applications increased.
Musical genres have no strict definitions and boundaries as they arise through a complex interaction between the public, marketing, historical, and cultural factors. We are going to create an application that accepts a music file and classify it in to genres.
Requirements
- Django (1.11)
- Numpy (1.12.1)
- Scikit-Learn (0.18.1)
- Scipy (0.19.0)
- Python-Speech-Features (0.5)
- Pydub (0.18.0)
Installation
git clone https://github.com/indrajithi/mgc-django.gitpip install -r requirements.txtpython manage.py migratepython manage.py runserver- App will run on
localhost:8000
Music Genre Classifier
Our app is written in Python using Django framework. We are using a trained Poly Kernel SVM for finding the genre.
Our web application uses the package mysvm which we developed to extract features and to find the genre.
We have developed a python package called mysvm for extracting features and classifying music. This package is added to our App. On receiving a request for genre label, we convert the file to .wav if it is in other format. Then the features are extracted from the audio file using mysvm.feature.extract (filename).
Prototype
We need to find the best classification algorithm that can be used in our App. Matlab is ideal to implement machine learning algorithms in minimum lines of code. Before making the App in python we made a prototype in Matlab.
Feature Extraction
We chose to extract MFCC from the audio files as the feature. For finding MFCC in Matlab, we have used HTK MFCC MATLAB toolkit. The output will be a matrix of 13n dimensional vector. Where n depends on the total duration of the audio. 13(100*sec).
While feature extraction we were getting ‘nan’(not a number) and infinity in the output. This is usually caused be a division by zero or a very small number closed to 0 resulting in infinity/nan in the output. This could be a regular result or some algorithm or implementation error in the MFCC toolkit. To overcome this situation, we have set nan or infinity entries in the feature array to 0.
Principal Component Analysis.
Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components (or sometimes, principal modes of variation) [7]. After doing a PCA on the data we got 90% variance and should reduce the feature dimension.
[input2, eigvec, eigvalue] = pca (ds. input);
cumvar = cumsum(eigvalue); //cumulative sum n(n+1)/2
cumvarpercent = cumvar/cumvar(end)*100;
Dimensionality reduction
Various researchers take statistics such as mean variance IQR, etc., to reduce the feature dimension. Some researchers model it using multivariate regression and some fit it to a Gaussian mixture model. Here we are taking the mean and upper diagonal variance of 13*n MFCC coefficients. The result is a feature vector of size 104.
%Reducing Feature Dimeansion
mf = mean(mm,2); %row mean
cf = cov(mm'); % covariance
ff = mf;
for i=0:(size(mm,1)-1)
ff = [ff;diag(cf,i)]; %use diagonals
end
t(:,end+1) = ff(:,1);
Classification
K-nearest neighbors (KNN)
Principle is that the data instance of the same class should be closer in the feature space. For a given data point x of unknown class, we can compute the distance between x and all the data points in the training data and assign the class determined by k nearest points of x.
Suppose we are given training dataset of n points.
{(x1,y1),(x2,y2)…(xn,yn)}
Where (xi,yi) represents data pair i.
xi- feature vector
yi- target class
For a new data point x the most likely class is determined by finding the distance from all training data points (Euclidian distance). The output class will be the class which k nearest neighbors belongs to. K is a predefined integer (k=1, k=2, k=3.)
Logistic Regression
Logistic Regression is one of the widely used classification algorithm. This algorithm is used in medical as well as business fields for analytics and classification. This model has the hypothesis function 0 ≤h (x) ≤ 1. Where hθ(x) = 11 + e-θTx called as Sigmoid or Logistic Function. For binary class classification y ∈{0, 1}. The output of this classifier will be a probability of the given input belonging to class 1. Ifhθ(x)outputs 0.7 it means that the given input has 70% chance of belonging to class 1. Since we have 10 genre classes y ∈{0, 1 .. 9}we used one-vs-all method for classification.
Python package mysvm
We developed a python package called mysvm which contains three modules: features, svm, acc. These are used by the web application in feature extraction and finding genre. This package also contains many other functions to do complicated feature extraction and classification.
├── acc.py
├── data
│ ├── classifier_10class.pkl
│ ├── classifier_10class_prob.pkl
│ ├── cmpr.pkl
│ └── Xall.npy
├── feature.py
├── __init__.py
├── svm.py
feature
This module is used to extract MFCC features from a given file. It contains the following functions.
- extract (file): Extract features from a given file. Files in other formats are converted to .wav format. Returns numpy array.
- extract_all (audio_dir): Extracts features from all files in a directory.
- extract_ratio (train_ratio, test_ratio, audio_dir) : Extract features from all files in a directory in a ratio. Returns two numpy arrays.
- geny(n):
Generates
Yvalues fornclasses. Returns numpy array. - gen_suby(sub, n):
Generates
Yvalues for a subset of classes. Returns numpy array. - gen_labels( ): Returns a list of all genre labels.
- flattern( x) : Flatterns a numpy array.
svm
A Support Vector Machine (SVM) is a discriminative classifier formally defined by a separating hyperplane. In other words, given labeled training data (supervised learning), the algorithm outputs an optimal hyperplane which categorizes new examples. This module contains various functions for classification using support vector machines.
poly(X,Y): Trains a poly kernel SVM by fitting X, Y dataset. Returns a trained poly kernel SVM classifier.
fit ( training_percentage, fold): Randomly choose songs from the dataset, and train the classifier. Accepts parameter:
train_percentage, fold; Returns trained classifier.getprob (filename): Find the probabilities for a song belongs to each genre. Returns a dictionary mapping genre names to probability and a list of top 3 genres which is having probability of more than 0.15.
random_cross_validation (train_percentage,fold): Randomly cross validate with training percentage and fold. Accepts parameter:
train_percentage, fold;findsubclass (class_count): Returns all possible ways we can combine the classes. Accepts an integer as class count. Returns numpy array of all possible combination.
gen_sub_data (class_l): Generate a subset of the dataset for the given list of classes. Returns numpy array.
fitsvm (Xall, Yall, class_l, train_percentage, fold): Fits a poly kernel svm and returns the accuracy. Accepts parameter:
train_percentage; fold; Returns: classifier, Accuracy.best_combinations (class_l, train_percentage, fold): Finds all possible combination of classes and the accuracy for the given number of classes Accepts: Training percentage, and number of folds Returns: A List of best combination possible for given the class count.
getgenre (filename): Accepts a filename and returns a genre label for a given file.
getgenreMulti (filename): Accepts a filename and returns top three genre labels based on the probability.
acc
Module for finding the accuracy.
- get ( res, test ) :
Compares two arrays and returns the accuracy of their match.
Results
| Classifier | Accuracy | |
|---|---|---|
| K-Nearest Neighbors | 53% | |
| Logistic Regression | 54% | |
| SVM Linear Kernel | 52% | |
| SVM RBF Kernel | 12% | |
| SVM Poly Kernel | 64% | |
| SVM Poly Kernel 6 genre classes | 85% |
Conclusion
We have tried various machine learning algorithms for this project. Our aim is to get maximum accuracy. We have found from our research that we can a get maximum accuracy of 65% by using poly kernel SVM for 10 genre classes. We have also tried to find the best combination of genre classes which will result in maximum accuracy. If we choose 6 genre classes we were able to get an accuracy of 85%. We chose these labels for the Web Application [classical, hip-hop, jazz, metal, pop and rock]
For some songs we can say that it has feature of multiple genres. So we have also tried to get multiple label outputs based on the probability.